


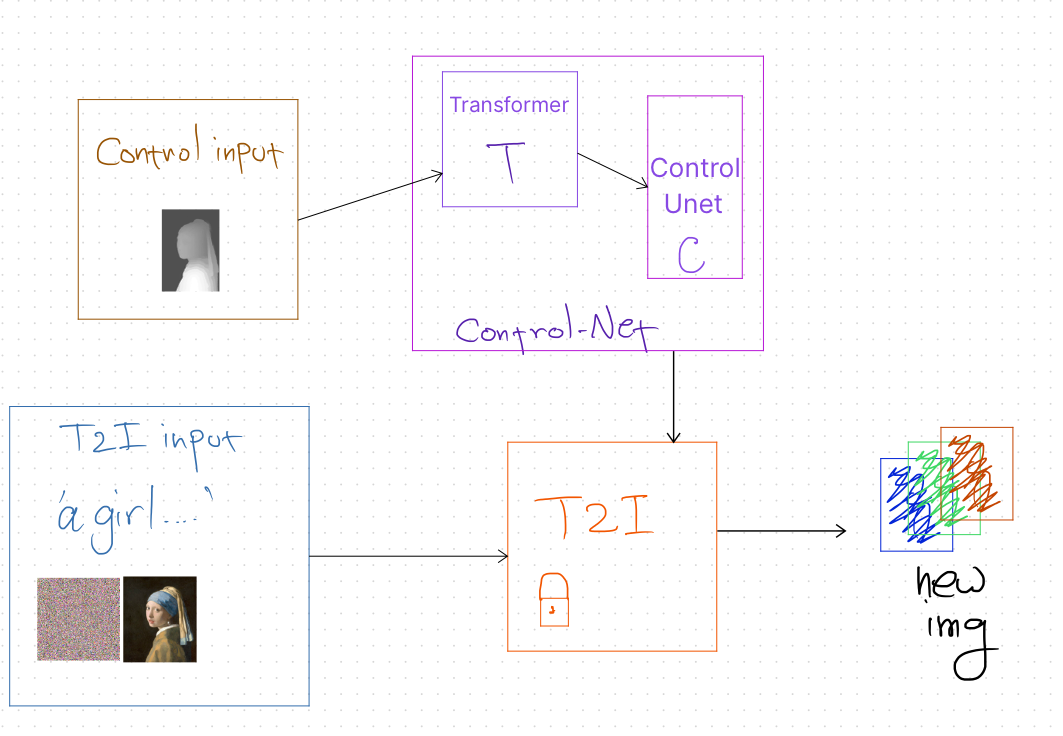

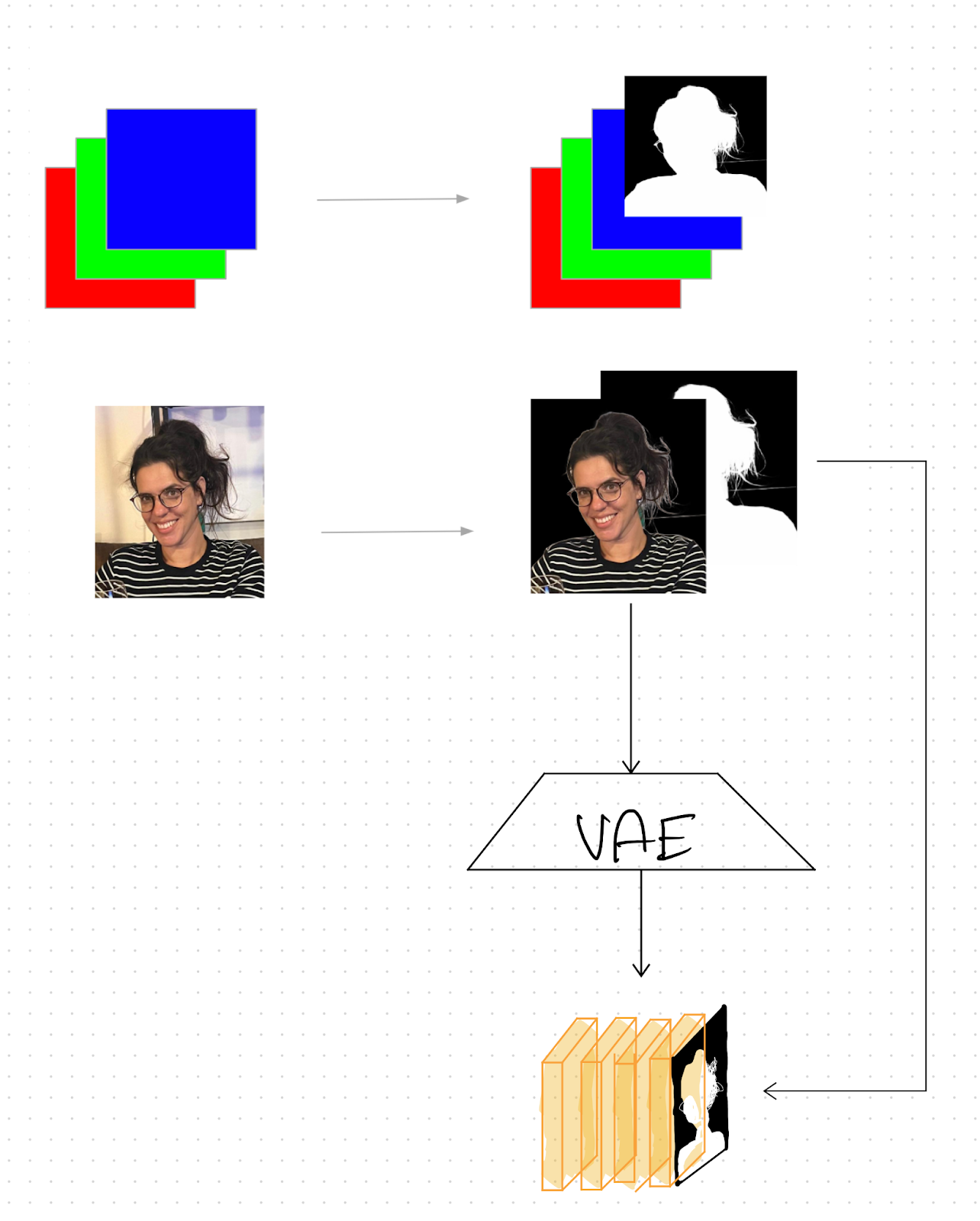

Bria AI Receives Two HPA Awards Recognizing Ethical Innovation and Transformative Impact on the Entertainment Industry
Today, Bria AI announced it has received two Hollywood Professional Association (HPA) Awards, recognizing the company's contributions to both the...


{kind=link}